1. 데이터프레임 생성
[소스]
import pandas as pd
student_list = [{'name' : 'John',
'major' : "Computer Science",
'sex' : "male"},
{'name' : 'Nate',
'major' : "Computer Science",
'sex' : "male"},
{'name' : 'Edward',
'major' : "Computer Science",
'sex' : "male"},
{'name' : 'Zara',
'major' : "Psychology",
'sex' : "famale"},
{'name' : 'John',
'major' : "Computer Science",
'sex' : "male"}]
df = pd.DataFrame(student_list, columns = ['name', 'major', 'sex'])
[결과]

위와 같이 데이터프레임을 생성해줍니다.
2. 중복된 행 확인, 제거
[중복확인 소스]
df.duplicated()[중복확인 결과]

위와 같이 "True"와 "False"로 중복할 수 있으며 "True"의 의미는 중복된 행을 뜻합니다.
이제 중복된 행을 제거해보겠습니다.
[중복된 행 제거 소스]
df.drop_duplicates()[중복된 행 제거 결과]

인덱스 0번과 4번이 중복되었지만 위 소스코드의 실행결과 중복된 행이 제거 된 것을 확인할 수 있습니다.
3. 중복된 열 확인, 제거
[데이터프레임 복구]

[컬럼명 "name" 기준 데이터 중복확인 소스]
df.duplicated(['name'])[컬럼명 "name" 기준 데이터 중복확인 결과]

인덱스 0과 4의 "name" 데이터를 살펴보면 "John"이라는 값으로 데이터가 중복되는 것을 확인 할 수 있습니다.
[중복제거시 첫번째 중복값을 유지하는 소스]
df.drop_duplicates(['name'], keep = 'first')
[결과]
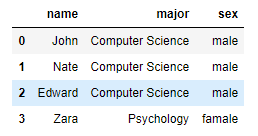
"keep"옵션에 "first"값을 주고 확인한 결과
인덱스 4의 행이 지워지고 인덱스 0의 행은 유지된 것을 확인할 수 있습니다.
[중복제거시 마지막의 중복값을 유지하는 소스]
df.drop_duplicates(['name'], keep = 'last')
[결과]

이번엔 반대로 "keep"옵션에 "last"값을 주어 확인한 결과
마지막행은 유지되고 첫번째 행이 제거된 것을 확인할 수 있습니다.
'프로그래밍 > Python' 카테고리의 다른 글
| [Python Pandas] 11. apply 함수 활용 (721) | 2020.12.10 |
|---|---|
| [Python Pandas] 10. 결측 데이터 관리(빈 값, NaN) (726) | 2020.12.10 |
| [Python Pandas] 8. 데이터 그룹 관리 (732) | 2020.12.09 |
| [Python Pandas] 7. 열 추가, 값 수정, 데이터 합치기 (734) | 2020.08.27 |
| [Python Pandas] 6. 행, 열 삭제 (723) | 2020.08.26 |