1. 데이터프레임 생성
[소스]
import pandas as pd
friends = [
{'age' : 15, 'job' : 'student'},
{'age' : 25, 'job' : 'developer'},
{'age' : 30, 'job' : 'teacher'}
]
df = pd.DataFrame(friends,
index = ['John', 'Jenny', 'Nate'], #행 인덱스 생성
columns = ['age', 'job']) #열 인덱스 생성
[결과]

2. 문자 Index 삭제 (2가지 방법)
[방법1]
[소스]
df = df.drop(['John', 'Nate']) #'John', 'Nate' Index 삭제[결과]

"John"과 "Nate" 인덱스가 삭제된 것을 확인 할 수 있습니다.
[방법2]
[소스]
df.drop(['John', 'Nate'], inplace = True)[결과]
"inplace=True" 옵션의 경우 변경된 데이터프레임을 적용하는 옵션으로 "df = df.drop(['John', 'Nate'])"와 같이 'df' 담을 필요없이 바로 적용이 가능합니다.
3. 숫자 Index 삭제
[데이터프레임 생성]
import pandas as pd
friends = [
{'name' : 'John', 'age' : 15, 'job' : 'student'},
{'name' : 'Ben','age' : 25, 'job' : 'developer'},
{'name' : 'Jenny','age' : 30, 'job' : 'teacher'}
]
df = pd.DataFrame(friends,
columns = ['name','age', 'job']) #열 인덱스 생성
[결과]
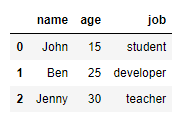
위와 같이 숫자로 된 Index를 생성합니다.
이제 Index 0, 2번을 삭제하는 코드를 만들고 결과를 출력해보겠습니다.
[소스]
df = df.drop(df.index[[0,2]])[결과]

이처럼 Index 0, 2번이 삭제된 것을 확인 할 수 있습니다.
4. 컬럼 삭제
[데이터프레임 생성]
import pandas as pd
friends = [
{'name' : 'John', 'age' : 15, 'job' : 'student'},
{'name' : 'Ben','age' : 25, 'job' : 'developer'},
{'name' : 'Jenny','age' : 30, 'job' : 'teacher'}
]
df = pd.DataFrame(friends,
columns = ['name','age', 'job']) #열 인덱스 생성[결과]
"age" 컬럼을 삭제하는 소스를 만들고 출력해보도록 하겠습니다.
[소스]
df.drop('age', axis=1)[결과]

여기서 "axis=1"의 의미는 컬럼을 뜻합니다.
"age"컬럼이 삭제된 것을 확인 할 수 있습니다.
'프로그래밍 > Python' 카테고리의 다른 글
| [Python Pandas] 8. 데이터 그룹 관리 (732) | 2020.12.09 |
|---|---|
| [Python Pandas] 7. 열 추가, 값 수정, 데이터 합치기 (734) | 2020.08.27 |
| [Python Pandas] 5. 행,열 선택 필터 및 수정 (729) | 2020.08.21 |
| [Python Pandas] 4. 데이터프레임 CSV 파일 저장 (707) | 2020.08.20 |
| [Python Pandas] 3. 데이터프레임 생성(Dictionaly , List) (751) | 2020.08.20 |