1. 데이터 프레임 생성
[소스]
student_list = [
{'name' : 'John', 'major' : "Computer Science", 'sex' : "male"},
{'name' : 'Nate', 'major' : "Computer Science", 'sex' : "male"},
{'name' : 'Abraham', 'major' : "Physic", 'sex' : "male"},
{'name' : 'Brian', 'major' : "Psychology", 'sex' : "male"},
{'name' : 'Janny', 'major' : "Psychology", 'sex' : "fmale"},
{'name' : 'Yuna', 'major' : "Economics", 'sex' : "fmale"},
{'name' : 'Jeniffer', 'major' : "Economics", 'sex' : "fmale"},
{'name' : 'Edward', 'major' : "Computer Science", 'sex' : "male"},
{'name' : 'Zara', 'major' : "Psychology", 'sex' : "fmale"},
{'name' : 'Wendy', 'major' : "Economics", 'sex' : "fmale"},
{'name' : 'Sera', 'major' : "Psychology", 'sex' : "fmale"}
]
df = pd.DataFrame(student_list, columns = ['name', 'major', 'sex'])
[결과]

데이터 프레임을 생성하였습니다.
2. 데이터 그룹화
[소스]
groupby_major = df.groupby('major')
groupby_major.groups첫째줄은 major를 기준으로 같은 데이터 끼리 묶는 소스입니다.
둘째줄은 묶여진 데이터들의 인덱스 값들을 확인할 수 있는 소스입니다.
표를 참고하여 예상되는 인덱스 값들은 아래와 같습니다.
'Computer Science': [0, 1, 7],
'Economics': [5, 6, 9],
'Physic':[2],
'Psychology':[3, 4, 8, 10]
출력이 맞을지 확인해 보겠습니다.
[결과]

예상대로 그룹화 되었습니다.
이제 데이터를 출력해보겠습니다.
3. 데이터 출력
[소스]
for name, group in groupby_major:
print(name + " : " + str(len(group)))
print(group)
print()[결과]

for문을 돌며 그룹화된 데이터의 수와 그룹별로 묶인 데이터를 출력하고 있습니다.
그룹화된 데이터에 "count" 컬럼을 추가 하고 싶습니다.
이럴땐 어떻게 해야할까요?
4. 그룹화된 데이터에 컬럼추가
[소스]
df_major_cnt = pd.DataFrame( {'count' : groupby_major.size() }).reset_index()
[결과]
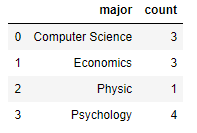
위의 소스내용의 의미는 "count"컬럼을 추가 하고 그룹화된 "major"의 데이터 갯수만큼 "count"에 입력을 하고 있습니다. 그리고 인덱스를 리셋시키는 방법으로 동작을 합니다.
'프로그래밍 > Python' 카테고리의 다른 글
| [Python Pandas] 10. 결측 데이터 관리(빈 값, NaN) (726) | 2020.12.10 |
|---|---|
| [Python Pandas] 9. 중복제거 (754) | 2020.12.09 |
| [Python Pandas] 7. 열 추가, 값 수정, 데이터 합치기 (734) | 2020.08.27 |
| [Python Pandas] 6. 행, 열 삭제 (723) | 2020.08.26 |
| [Python Pandas] 5. 행,열 선택 필터 및 수정 (729) | 2020.08.21 |