1. 데이터프레임 생성
[소스]
import pandas as pd
date_list = [{'yyyy-mm-dd' : '2000-06-27'},
{'yyyy-mm-dd' : '2002-09-24'},
{'yyyy-mm-dd' : '2005-12-20'}]
df = pd.DataFrame(date_list, columns = ['yyyy-mm-dd'])[결과]

날짜가 기록된 데이터프레임을 만들어 주었습니다.
2. apply() 함수를 통한 데이터 관리
[소스]
def extract_year(column):
return column.split("-")[0]
df['year'] = df['yyyy-mm-dd'].apply(extract_year)
[결과]
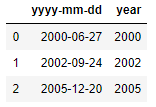
먼저 사용자 정의 함수를 살펴보면 "extract_year()"이라는 함수를 만들고 인자로
전달받은 데이터를 '-' 문자로 나누어 리스트로 담아 첫번째 원소를 리턴하고 있습니다.
만약 "2020-06-27"이라는 데이터를 인자로 받으면 ['2020', '06', '27]의 형태인 리스트로 변환되고
이 리스트의 첫번째 원소인 "2020"이 리턴됩니다.
마지막 줄 소스코드에 대해 설명을 하면 데이터프레임의 'yyyy-mm-dd'라는 컬럼의 데이터를 모두 가져와 apply() 함수에 인자로 넣어주고 있습니다.
그리고 리턴된 결과를 "year"이라는 컬럼에 대입하는 소스입니다.
이렇듯 for문 없이 아주 간편하게 사용자 함수를 적용할 수 있습니다.
3. apply()함수를 이용한 나이 구하기
[데이터프레임]
[소스]
def get_age(year, current_year):
return current_year - int(year)
df['age'] = df['year'].apply(get_age, current_year = 2020)[결과]
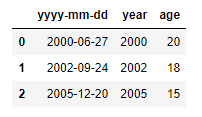
2번과 동일한 방식으로 진행하였으며 "age"컬럼을 추가하여 각각의 나이를 구해보았습니다.
'프로그래밍 > Python' 카테고리의 다른 글
| Python SFTP(SSH기반의 FTP)를 이용한 파일 업로드, 다운로드 기능 (149) | 2023.09.12 |
|---|---|
| [Python Pandas] 10. 결측 데이터 관리(빈 값, NaN) (726) | 2020.12.10 |
| [Python Pandas] 9. 중복제거 (754) | 2020.12.09 |
| [Python Pandas] 8. 데이터 그룹 관리 (732) | 2020.12.09 |
| [Python Pandas] 7. 열 추가, 값 수정, 데이터 합치기 (734) | 2020.08.27 |